There is a minor issue lingering which we currently have no working solution.
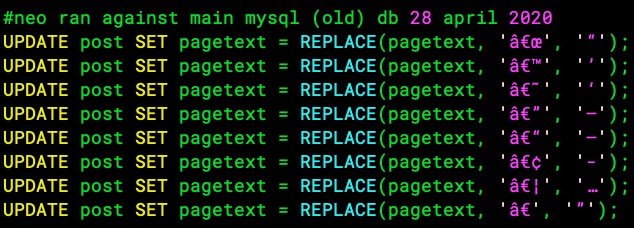
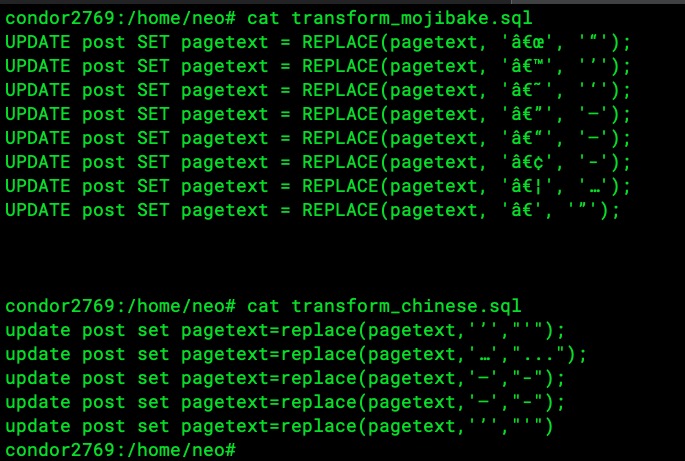
For example, see this pagetext in the original (old) forum mysql DB (continued thats to hicksd8 for finding these and for looking into this interesting topic):
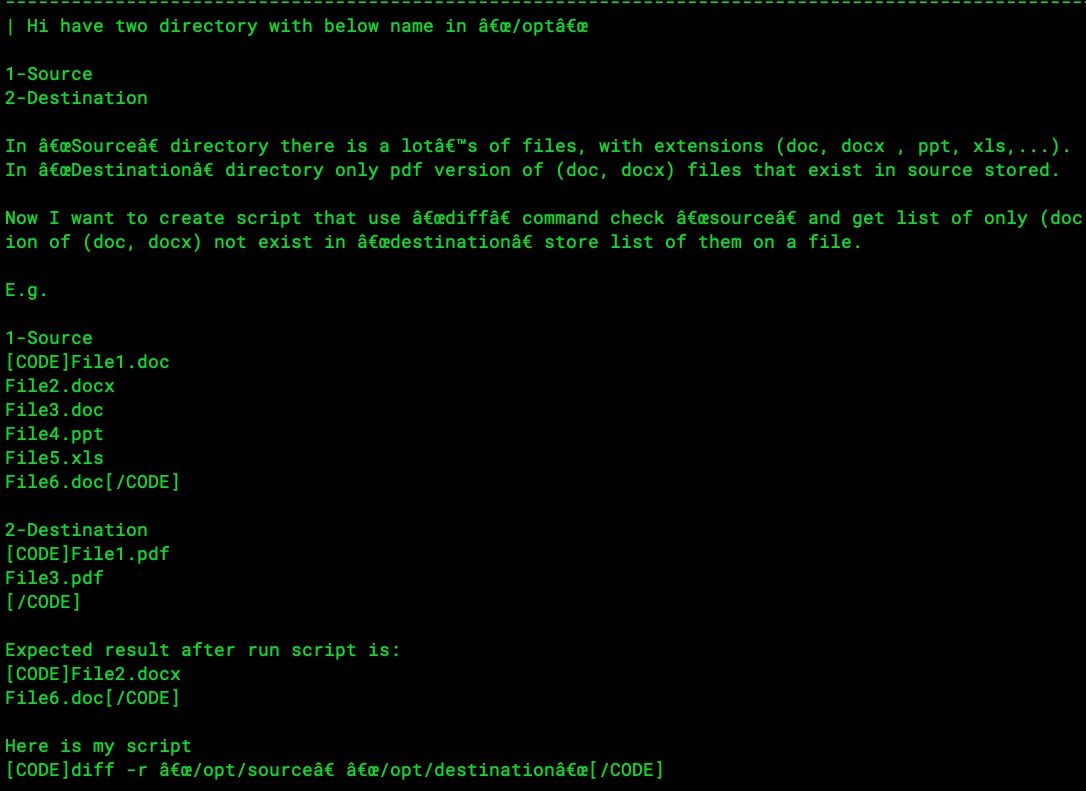
From original DB:
| Hi have two directory with below name in "/opt"
1-Source
2-Destination
In "Source"� directory there is a lot's of files, with extensions (doc, docx , ppt, xls,...).
In "Destination"� directory only pdf version of (doc, docx) files that exist in source stored.
Now I want to create script that use "diff"� command check "source"� and get list of only (doc, docx) files after that look for related pdf file in "Destination"� if pdf version of (doc, docx) not exist in "destination"� store list of them on a file.
E.g.
1-Source
File1.doc
File2.docx
File3.doc
File4.ppt
File5.xls
File6.doc
2-Destination
File1.pdf
File3.pdf
Expected result after run script is:
File2.docx
File6.doc
Here is my script
diff -r "/opt/source"� "/opt/destination"
Any recommendation?
Thanks
UPDATE
Follow below post and work like charm:
comm -23 <(find dir1 -type f -exec bash -c 'basename "${0%.*}"' {} \; | sort) <(find dir2 -type f -exec bash -c 'basename "${0%.*}"' {} \; | sort)
test1
filenames - diff two directories, but ignore the extensions - Unix & Linux Stack Exchange
[/NOPARSE][/CODE]
Here is the original post:
https://www.unix.com/unix-for-beginners-questions-and-answers/284088-compare-two-directory-find-differents.html
Here is the migrated post:
https://community.unix.com/t/compare-two-directory-and-find-differents/377962
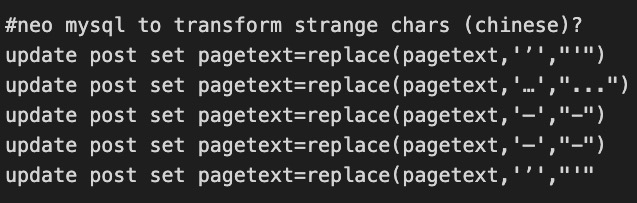
Note that some of the strange chars in the original DB become the "unknown unicode char" \uFFFD in the new DB:
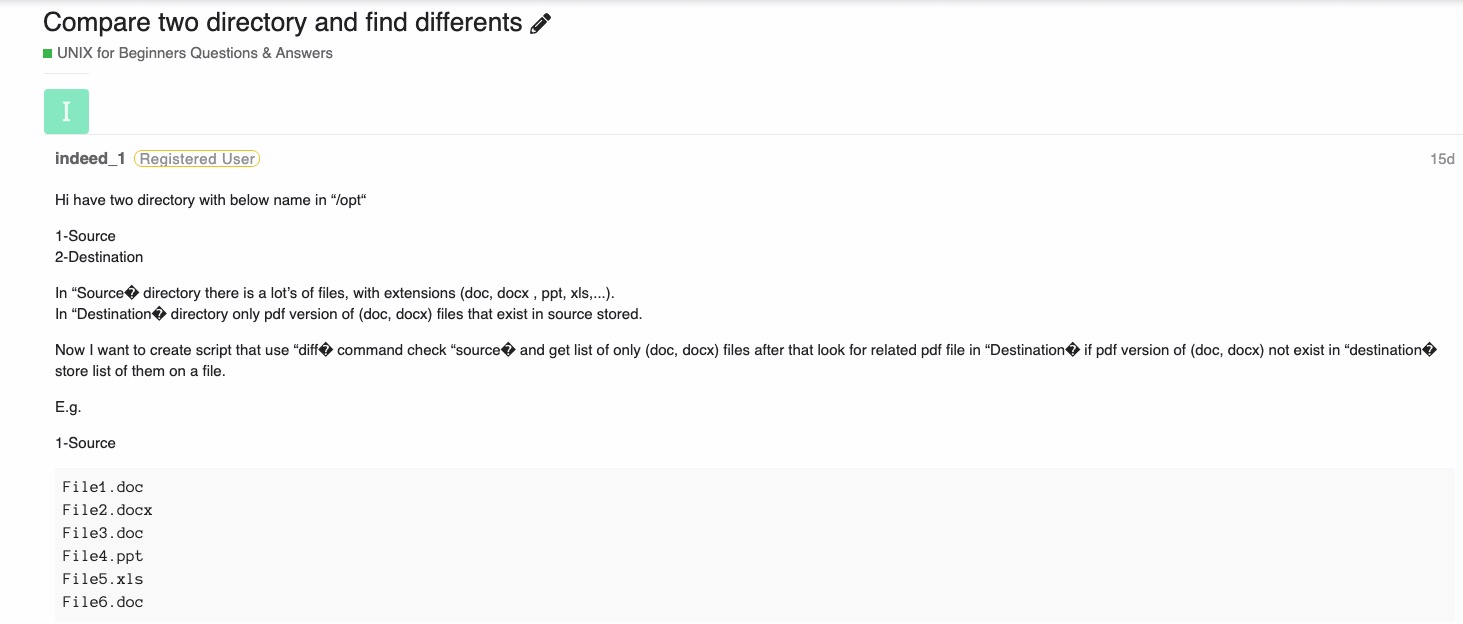
This encoding issue is very noticeable in spam in our database (mostly from non-English speakers and countries).
We see this occasionally in the DB from other non-English speakers and do not have a perfect solution for this issue, so far.