I create a CGI in bash/html.
My awk script looks like :
echo "<table>"
for fn in /var/www/cgi-bin/LPAR_MAP/*;
do
echo "<td>"
echo "<PRE>"
awk -F',|;' -v test="$test" '
NR==1 {
split(FILENAME ,a,"[-.]");
}
$0 ~ test {
if(!header++){
print "DATE ========================== : " a[4]
}
print ""
print "LPARS :" $2
print "RAM : " $5
print "CPU 1 : " $6
print "CPU 2 : " $7
print ""
print ""
}' $fn;
echo "</PRE>"
echo "</td>"
done
echo "</table>"
This script allow to analyze 276 csv files that looks like :
MO2PPC20;mo2vio20b;Running;VIOS 2.2.5.20;7;1.0;2;DefaultPool;shared;uncap;192 MO2PPC20;mo2vio20a;Running;VIOS 2.2.5.20;7;1.0;2;DefaultPool;shared;uncap;192 MO2PPC21;mplaix0311;Running;AIX 7.1 7100-05-02-1832;35;0.6;4;DefaultPool;shared;uncap;64 MO2PPC21;miaibv194;Running;AIX 6.1 6100-09-11-1810;11;0.2;1;DefaultPool;shared;uncap;64 MO2PPC21;mplaix0032;Running;AIX 6.1 6100-09-11-1810;105;4.0;11;DefaultPool;shared;uncap;128 MO2PPC21;mplaix0190;Running;Unknown;243;4.9;30;DefaultPool;shared;uncap;128 MO2PPC21;mo2vio21b;Running;VIOS 2.2.6.10;6;1.5;3;DefaultPool;shared;uncap;192 MO2PPC21;miaibv238;Running;AIX 7.1 7100-05-02-1810;10;0.5;1;DefaultPool;shared;uncap;64 MO2PPC21;mo2vio21a;Running;VIOS 2.2.6.10;6;1.5;3;DefaultPool;shared;uncap;192 MO2PPC21;miaibv193;Running;AIX 6.1 6100-09-11-1810;12;0.2;1;DefaultPool;shared;uncap;64 MO1PPC17;miaibe03;Running;AIX 5.2 5200-10-08-0930;25;null;3;null;ded;share_idle_procs;null MO1PPC17;miaiba12;Running;AIX 5.2 5200-10-08-0930;17;null;2;null;ded;share_idle_procs;null MO1PPC17;miaibf03;Running;AIX 5.2 5200-10-08-0930;30;null;3;null;ded;share_idle_procs;null MO1PPC17;miaibc05;Running;AIX 5.2
5200-10-08-0930;40;null;2;null;ded;share_idle_procs;null
And allow to display them in my CGI like that :
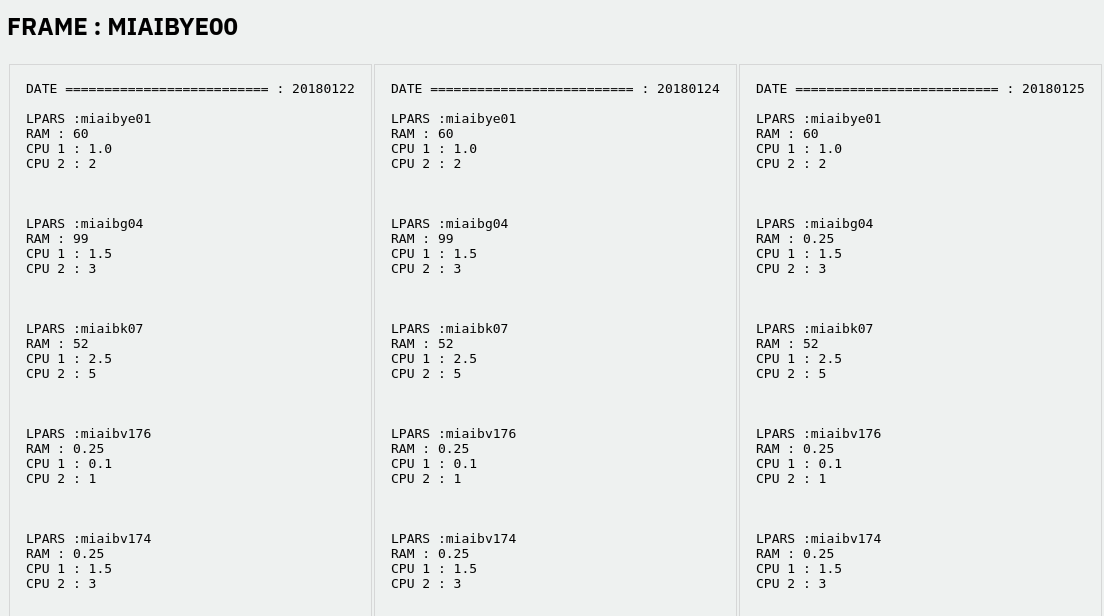
The numbers of columns is equal at the number of csv to analyze.
As you can see in the screenshot, some lines are sometimes the same in each csv files. The idea is to delete the lines that are the same in all my csv files.
I know the command :
awk '!a[$0]++'
But I don't know how to put it in my awk script... Do you have any idea ?
Thank you ! 
