Hello,
Welcome to the forum ! We hope you find this to be a friendly and helpful place, and that you enjoy your time here.
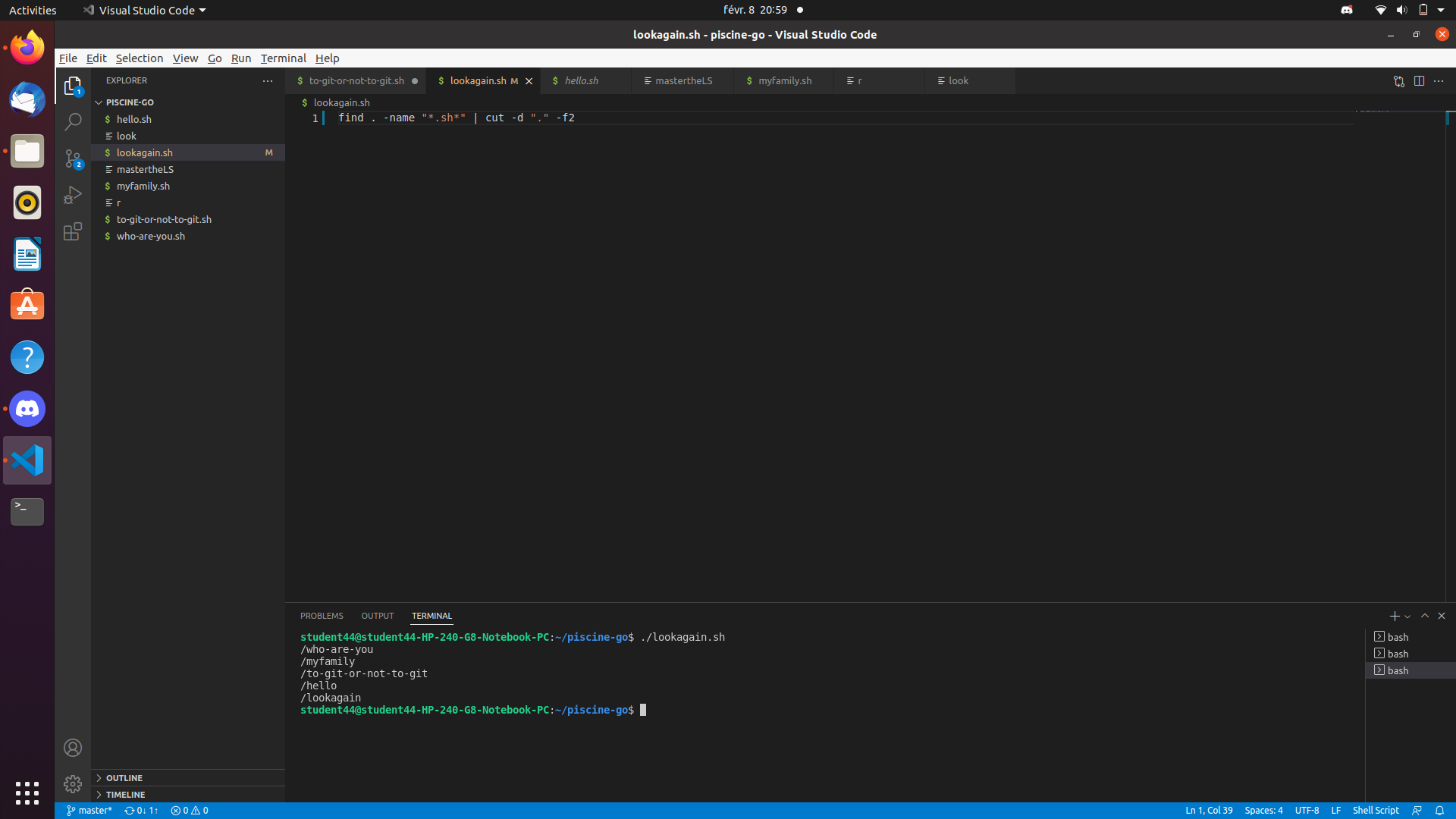
The explanation for this behaviour is that the find command will always return the full path to what it finds, relative to the path it is told to start its search from.
Let's demonstrate with a test. Imagine that we have the following directory on a system, from which we wish to start searching for something with find:
$ pwd
/home/unixforum/385357/find-test
$
Now, if we give the full path to this directory to find, we'll get an absolute path for each of our results, like so:
$ find /home/unixforum/385357/find-test -type f -name "test.*"
/home/unixforum/385357/find-test/dir1/test.doc
/home/unixforum/385357/find-test/dir1/subdir1/test.txt
/home/unixforum/385357/find-test/dir3/test.jpeg
/home/unixforum/385357/find-test/dir2/test.xlsx
/home/unixforum/385357/find-test/dir2/subdir1/test.xlsx
$
But if we start our find from within /home/unixforum/385357/find-test, and use the current directory as the root of our find path, our results instead look like this:
$ pwd
/home/unixforum/385357
$ find . -type f -name "test.*"
./find-test/dir1/test.doc
./find-test/dir1/subdir1/test.txt
./find-test/dir3/test.jpeg
./find-test/dir2/test.xlsx
./find-test/dir2/subdir1/test.xlsx
$
So now, we get a relative path, rather than an absolute path - that is, a valid path to our results, but only if taken from the current working directory (which is what we told find our search path was).
In summary, then: the find command will always return the filesystem path to your search results starting from the top of the given search path, and not merely the filenames of what it finds. This allows the results returned to be validly and simply used with other commands, scripts or programs, since a filename on its own without the path to where it lives isn't really useful for much.
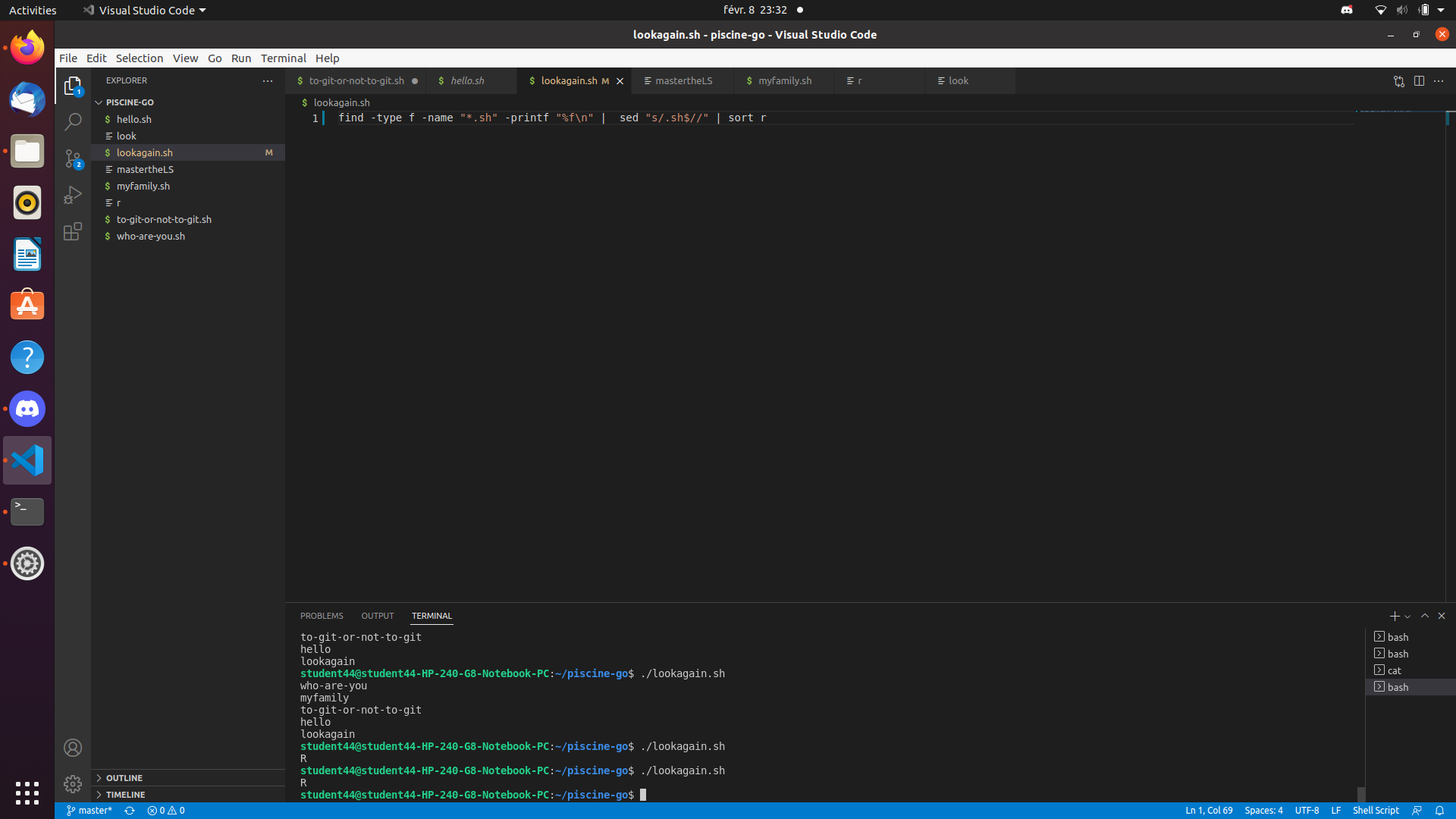
If you really do genuinely only want the filenames for some reason, and not the full path to whatever was found, you could do this instead:
$ find /home/unixforum/385357/find-test/ -type f -name "test.*" -printf "%f\n"
test.doc
test.txt
test.jpeg
test.xlsx
test.xlsx
$
Here, we use the -printf argument to format our results, and we specify that we only wish to print the filename, represented by %f. Note that this requires GNU find in order to work, which is what you'll be using if you're on Linux (which your question implies you are).
Hope this helps ! If not, or if you have any further questions, please let us know and we can take things from there.