IV. ChatGPT in a Nutshell - Houston, Have a Problem.
I have learned many things since ChatGPT was released by OpenAI and will summarize "in a nutshell" in this post.
First of all, most users of ChatGPT and generative "AI", in general, do not understand the underlying core "AI" technologies. This lack of basic understanding of various technologies is usually not dangerous for society. After all, you don't need to understand how radio waves work to listen to your car radio and you don't need to understand video compression to watch television.
However, in the case of generative AI, this basic lack of understanding has already created conflicts in society. So, before proceeding on the social issues, let me provide a high-level description of ChatGPT (and generative AI in general) .
In a Nutshell
ChatGPT, and generative AI technology in general, is a deep neural network-based text prediction engine based on a large language model. This technology has no "awareness" or "domain knowledge" about facts, except the domain of generating human like language output. It's basically a type of powerful text-autocompletion engine which is specialized to pay attention to text and to predict the next sequence of text using statistics embedded within a large language model.
This means, when you send this text to ChatGPT:
What is a dog?
ChatGPT will first filter and moderate the text above to insure the text is not in violation of the OpenAI use policies. If the text passes the filters and moderation policies, then the text is sent to be processed by it's generative "AI" core.
The generative "AI" core, uses some sophisticated algorithms to break the text into tokens based on human speech patterns and uses more algorithms to determine how to "pay attention" or "focus" on the tokens as they are submitted to the "next sequencing" prediction engine.
After this text-completion process has completed, the output is filtered to insure the output, before presented to the user, is socially and politically acceptable and "good for business", etc.
So, basically user prompts are filtered and moderated, passed to a powerful auto-completion engine based on a large language model, and then filtered and moderated again before presented back to the user.
In the ChatGPT reply above, ChatGPT has zero concept of animals or of dogs. However, what ChatGPT does have is a massive amount of data on human text about dogs. This data is used to predict the next sequence of text and create human-like speech output.
The Core Problem
ChatGPT is designed to produce very good human-like text. So, for the vast majority of users who use ChatGPT and other similar powerful generative AI models, the text is so well constructed that the results appear to come from a knowledgable human expert. However, in reality, nothing is further from the truth.
Since most users of generative "AI" do not understand that these "chatbots" are just generating text (blah, blah, blah....) a few tokens of human-like-text-at-a-time, without any domain knowledge of what it is generating, the vast majority of users confuse fact with fiction and reality with fantasy.
This type of generative "AI" performs well for fiction or fantasy writers who do not care about facts. However, for folks who need facts and not fiction, generative AI is more of a "con-man" than an "expert".
Many users of ChatGPT complain that when they ask ChatGPT to write a technical paper with references, ChatGPT will just "make up facts" and "make up references". Users expect ChatGPT to perform as an "expert system" which actually pays close attention to technical references; but what they get is a convincing language model which just fabricates references based on it's extensive language model of what references "look like". Sometimes, the dice can roll in the users favor and generate a "good reference" which further fools the user into thinking they are working with a domain expert and not a powerful auto-completion engine.
The same is true when a developer uses ChatGPT to help develop code. ChatGPT simply auto-completes code based on probability, not domain knowledge. This means that for mature programming languages with a tremendous amount of code examples in the public domain, there is a high probability the user will get an acceptable code snippet. In other words, it's pretty easy to get an acceptable method from ChatGPT for prompts like:
Write a "hello world" method in Python"
Or
Create an array of hashes using biological data in Ruby and sort based on a hash key.
However, when you go beyond basic, well-established programming examples, the codex models often generate fictional APIs, non-existent libraries, and "made up" parameters. For experienced software developers, these "fantasy" code-completions can be helpful as experienced developers can usually see that the code is "hallucinated nonsense" but it can be interesting and entertaining none-the-less.
The problem lies with the huge number of "ChatGPT programmers" who has little to no experience coding and they have no idea that ChatGPT is generating a completion based on a code library which was deprecated 4 years ago, and "making up" parameters and API calls "because the code fits the language model".
A similar problem exists with people using ChatGPT for social and political topics.
ChatGPT has no political or social knowledge. These generative "AI". algorithms just generate text based on a large language model. So, if the large majority of the corpus of data is "left leaning", the model will be biased to be "left leaning". This bias, of course, angers the "right". What happens next is that companies like OpenAI start filtering and moderating the output in response to various groups who are "offended". They have little to no choice because they cannot hope to generate revenue from language models that offended "just about everyone" when unfiltered!
So, in a nutshell, as we all know from Apollo space mission history:
"Uh, Houston, we've had a problem." - Apollo 13 spaceflight, 1970
We have a big problem actually.
Epilogue
As a software developer, I use both ChatGPT and GitHub Copilot when coding, which is often daily. I like having a "little bird" making suggestions and auto-completing code in Visual Studio Code. More-often-than-not the code suggestions are not what I am looking for, but they are are amusing and entertaining. The annoyance of these suggestions are better than "no suggestions at all"; so I am a monthly paid subscriber for GitHub Copilot.
Also, I use ChatGPT for coding as well. It's "hit-and-miss" and often I will end up confirming a ChatGPT suggestion using Google and confirming with an "online expert" post somewhere out their in the wild. I take all ChatGPT generated code with a huge "grain of salt" but these code suggestions often make good "first drafts" and do provide "good for thought" even when wrong. In other words, I'm. not sure if "copilot" is the right word to describe what is more like "voices from the back of the plane", but I don't think GitHub is going to rename their OpenAI-based extension:
GitHub - Voices from the Back of the Plane
Anyway, I doubt most passengers can come up with any code suggestions at all, so maybe the following is a more accurate title, but of course it's not "sellable":
GitHub - OpenAI LLM Code Completions
I see mostly danger ahead as generative AI becomes more engrained into human society and I fully understand the concerns voiced by folks who want to "slow down" and regulate generative AI. However, and unfortunately, "this ship has already sailed" and yes,
"Uh, Houston, we've had a problem."
Appendix
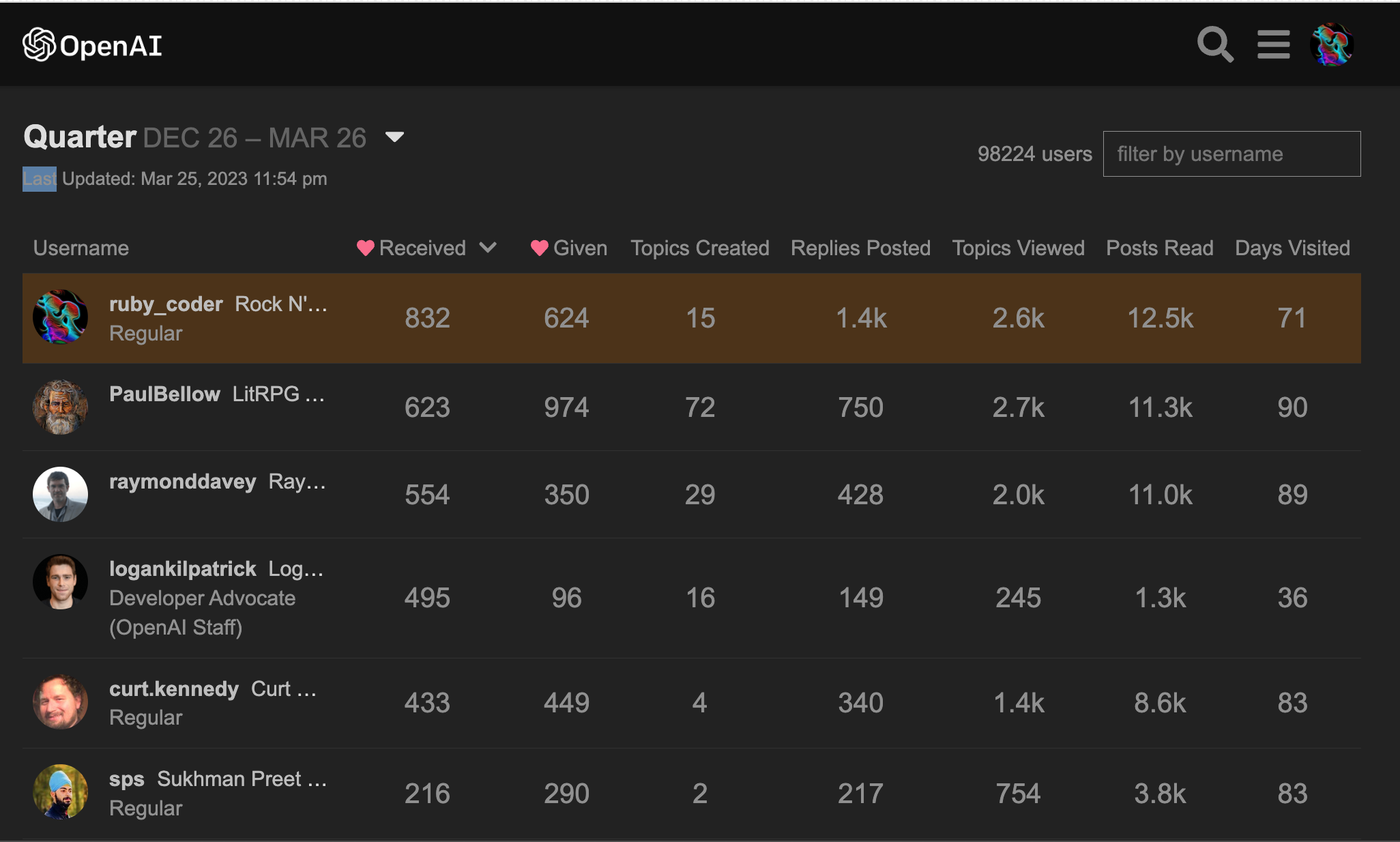
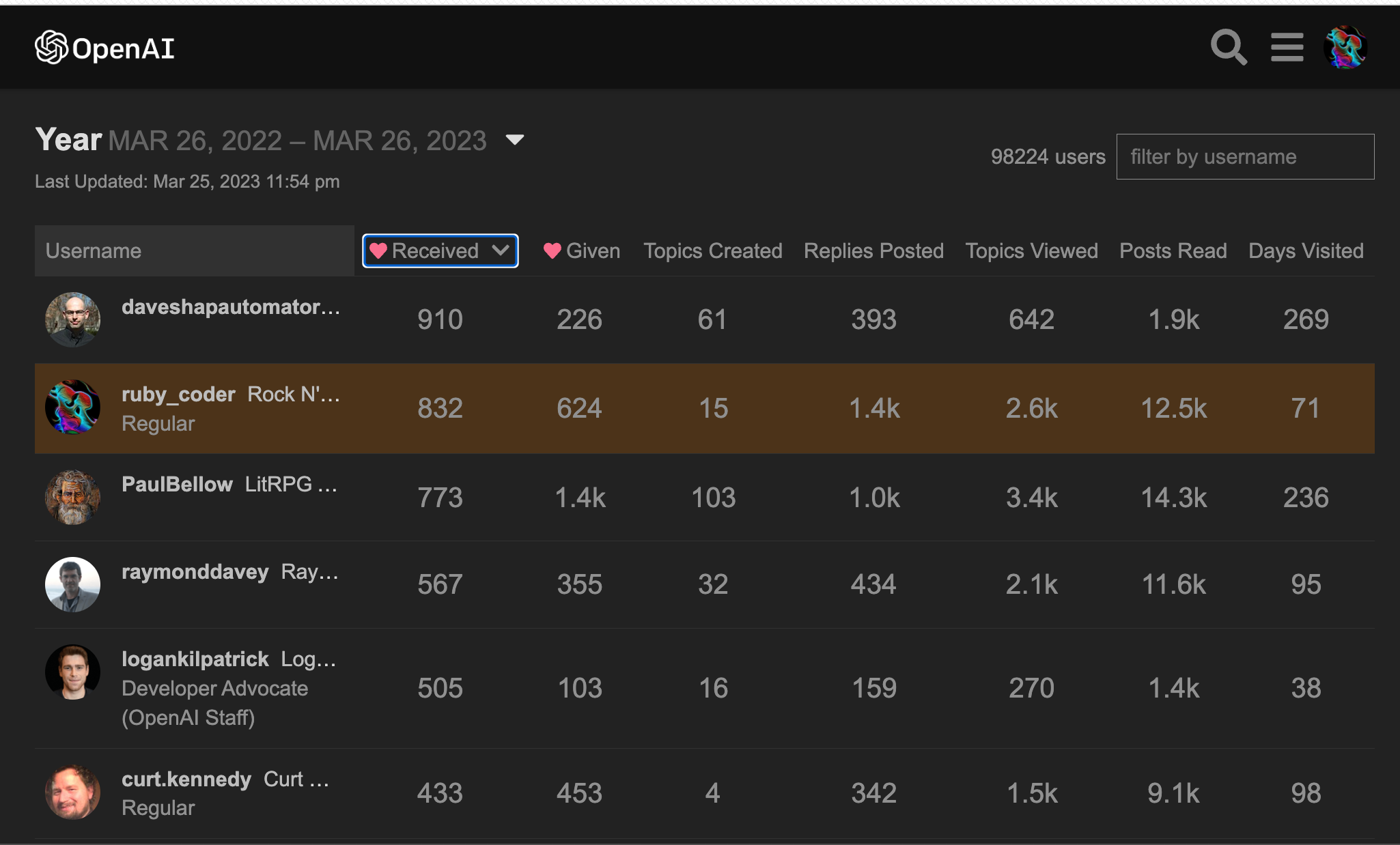
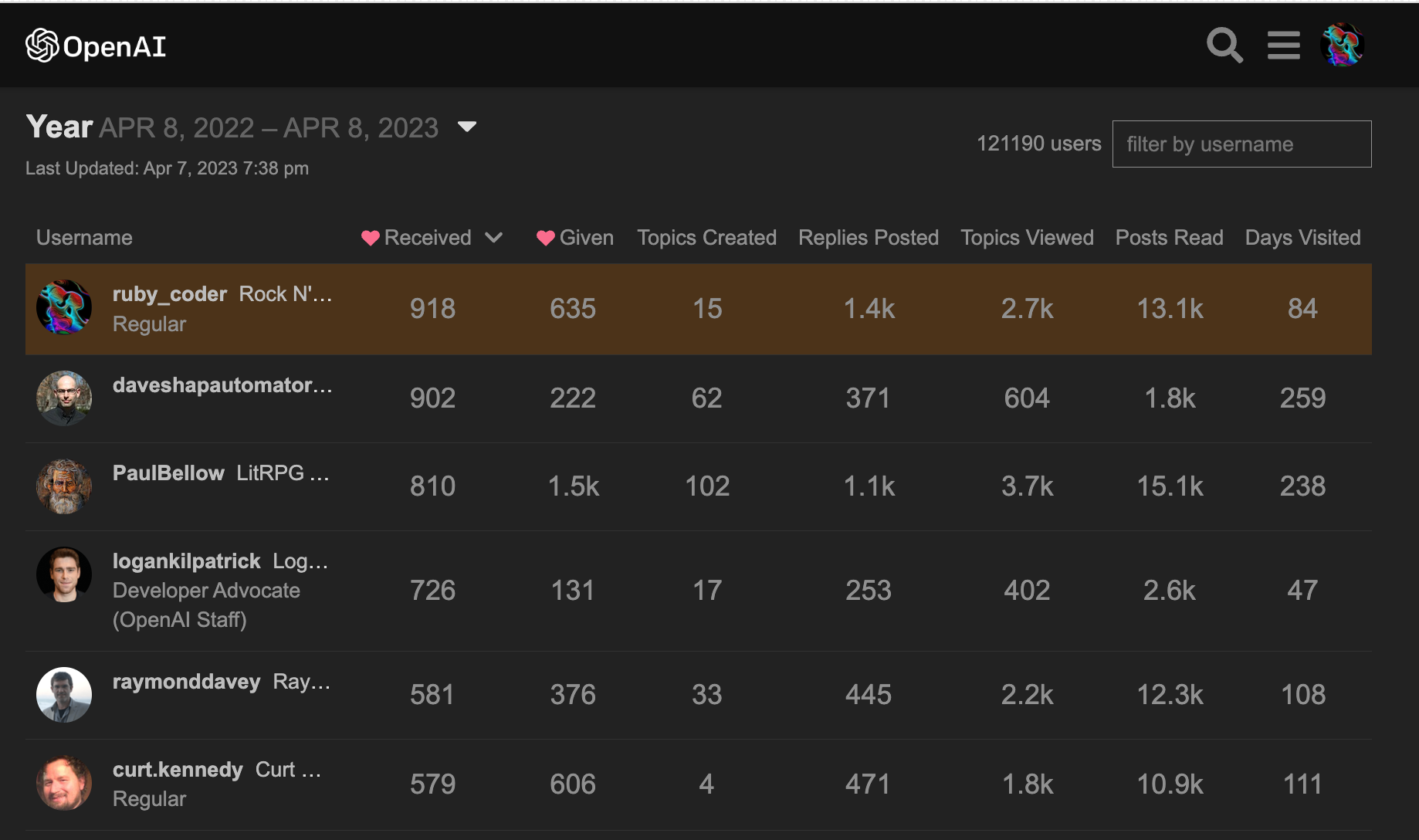
Retired from answering user API questions at the OpenAI Dev Community for around two weeks, still ranked the "most loved" member there (yearly and quarterly lists) with over 1,400 replies to members there. So, different than a generative AI chatbot, I know what I'm talking about and not "making things up" like chatbots do ....