I want to select a DOM element by CSS class and echo its textContent in the terminal.
I could download the webpage with curl or view it with lynx but I have no idea how to proceed from there.
I want to select a DOM element by CSS class and echo its textContent in the terminal.
I could download the webpage with curl or view it with lynx but I have no idea how to proceed from there.
a sample webpage file, the desired "CSS class" and the desired output would help.
This is the URL (I can't post a full link, I get an error saying that I can't put a link to that host):
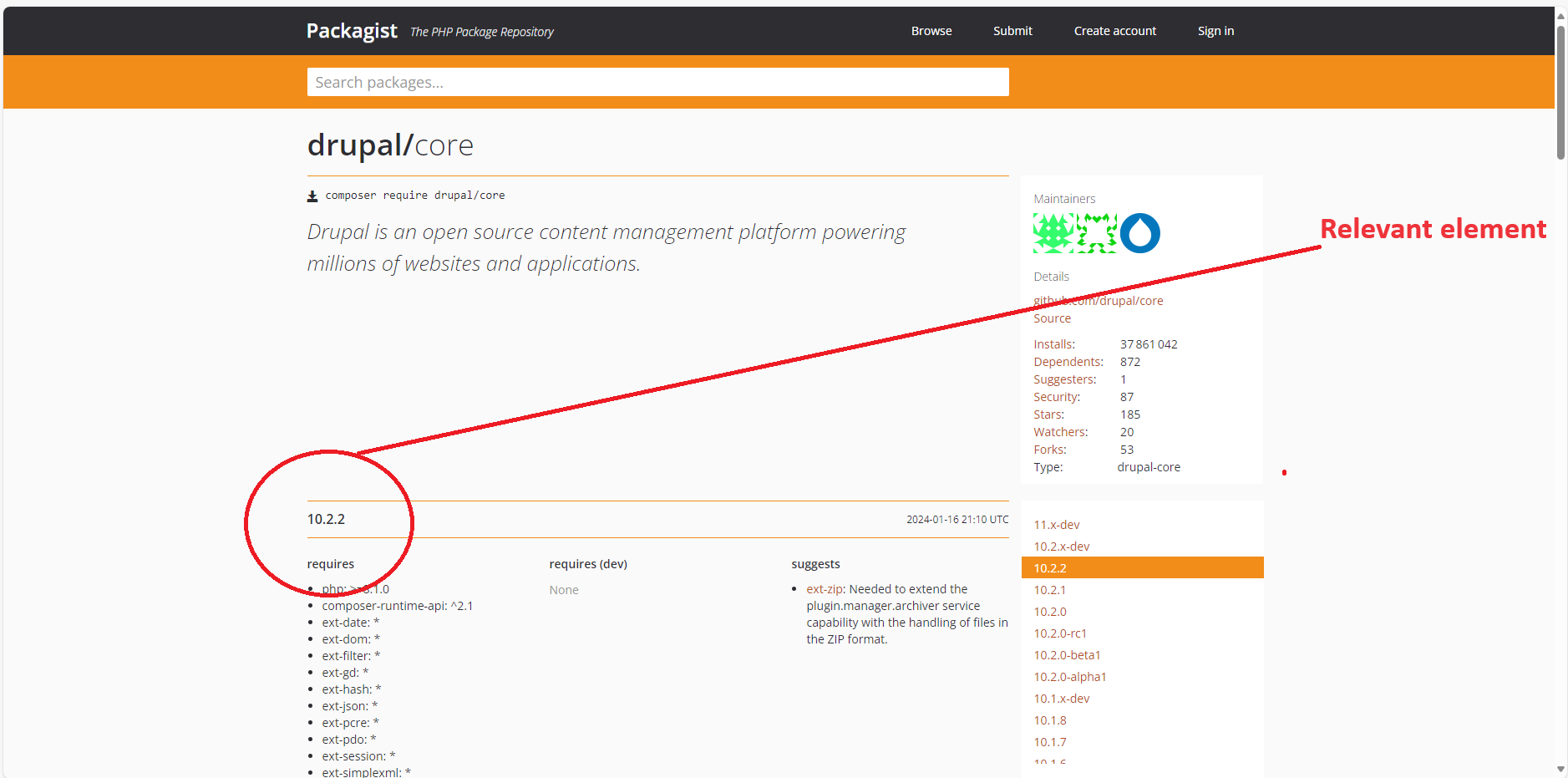
packagist.org/packages/drupal/coreThe element I want to get its textContent is the package version element.
As you can find, the CSS class of this element is version-number.
The output should be 10.2.2.
Without squinting too hard...something like this - YMMV:
$ curl -s https://packagist.org/packages/drupal/core | awk -F'[<>]' '$2~/^span.*version-number/ {print $3}'
10.2.2
Thanks
Do you know another way without awk?
I never learned awk, only sed and can't learn awk soon and would generally avoid working with something I didn't learn its elements yet.
This sed does about the same:
sed -n 's/^[^<]*<span class="version-number">\([^<]*\)<.*/\1/p'
EDIT: put " around version-number, thanks to the following comment.
curl -s https://packagist.org/packages/drupal/core | sed -nr '/.*span.*version-number.*/s/[^0-9.]*([0-9.]*).*/\1/p'
version-number is in between ", btw
using grep and cut:
curl -s https://packagist.org/packages/drupal/core | grep span.*version-number | cut -d'>' -f2 | cut -d'<' -f1