I am using Debian 8 "Jessie" that has GNU find 4.4.2
After running your commands on similarly sized files, here's my guess about what is happening.
When you say "-size nS", where "n" is an integer specifying "units of space" and "S" is the suffix (M, k etc.), then the find command searches for files that have a rounded up size of "nS".
That effectively means that the size of the file is > (n-1)S and <= nS.
So, as per this theory, "-size 1M" means files with "rounded up size of 1M", or sizes > 0M and <= 1M. 0M bytes = 0 bytes. Hence files with sizes 183, 2112 etc are displayed.
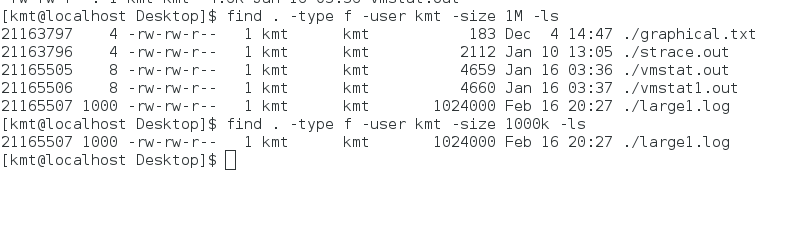
$ find . -type f -size 1M -ls
6029496 1000 -rw-r--r-- 1 r2d2 r2d2 1024000 Feb 17 02:32 ./large1.log
6029492 4 -rw-r--r-- 1 r2d2 r2d2 183 Feb 17 02:29 ./graphical.txt
6029493 4 -rw-r--r-- 1 r2d2 r2d2 2112 Feb 17 02:29 ./strace.out
6029494 8 -rw-r--r-- 1 r2d2 r2d2 4659 Feb 17 02:29 ./vmstat.out
6029495 8 -rw-r--r-- 1 r2d2 r2d2 4660 Feb 17 02:30 ./vmstat1.out
$
If you say "-size 2M", then it would mean files with "rounded up size of 2M", or sizes > 1M and <= 2M. That will not display anything, since there is no file with size > 1M or 1048576 bytes and <= 2M or 2097152 bytes.
$ find . -type f -size 2M -ls
$
Similar case could be argued for size 3M.
$ find . -type f -size 3M -ls
$
Now, in case of "-size = 1000k", notice that k = 1024 bytes, so it searches for files with rounded up size of 1000k i.e. sizes > 999k or (999 * 1024 =) 1022976 bytes and <= 1000k or (1000 * 1024 =) 1024000 bytes.
That displays your one file.
$ find . -type f -size 1000k -ls
6029496 1000 -rw-r--r-- 1 r2d2 r2d2 1024000 Feb 17 02:32 ./large1.log
$
To test this logic further, I created three files with sizes:
(1) 999k bytes - 1 byte = 1022975 bytes
(2) 999k bytes = 1022976 bytes
(3) 999k bytes + 1 byte = 1022977 bytes
using the following commands:
perl -e 'foreach (1..1022){foreach (1..999){print chr(97+int(rand(26)))}; print "\n"}' >large1_v1.log
perl -e 'foreach (1..1) {foreach (1..974){print chr(97+int(rand(26)))}; print "\n"}' >>large1_v1.log
perl -e 'foreach (1..1022){foreach (1..999){print chr(97+int(rand(26)))}; print "\n"}' >large1_v2.log
perl -e 'foreach (1..1) {foreach (1..975){print chr(97+int(rand(26)))}; print "\n"}' >>large1_v2.log
perl -e 'foreach (1..1022){foreach (1..999){print chr(97+int(rand(26)))}; print "\n"}' >large1_v3.log
perl -e 'foreach (1..1) {foreach (1..976){print chr(97+int(rand(26)))}; print "\n"}' >>large1_v3.log
My pwd now looks like this:
$ ls -l
total 4024
-rw-r--r-- 1 r2d2 r2d2 183 Feb 17 02:29 graphical.txt
-rw-r--r-- 1 r2d2 r2d2 1024000 Feb 17 02:32 large1.log
-rw-r--r-- 1 r2d2 r2d2 1022975 Feb 17 02:55 large1_v1.log
-rw-r--r-- 1 r2d2 r2d2 1022976 Feb 17 02:55 large1_v2.log
-rw-r--r-- 1 r2d2 r2d2 1022977 Feb 17 02:56 large1_v3.log
-rw-r--r-- 1 r2d2 r2d2 2112 Feb 17 02:29 strace.out
-rw-r--r-- 1 r2d2 r2d2 4660 Feb 17 02:30 vmstat1.out
-rw-r--r-- 1 r2d2 r2d2 4659 Feb 17 02:29 vmstat.out
$
Now specifying "-size 1000k" should display files large1.log and large1_v3.log since they both have sizes > 1022976 (999k) and <= 1024000 (1000k)
$ find . -type f -size 1000k -ls
6029496 1000 -rw-r--r-- 1 r2d2 r2d2 1024000 Feb 17 02:32 ./large1.log
6029500 1000 -rw-r--r-- 1 r2d2 r2d2 1022977 Feb 17 02:56 ./large1_v3.log
$
And "-size 999k" should display files large1_v1.log and large1_v2.log since they both have sizes > 1021952 (998k) and <= 1022976 (999k)
$ find . -type f -size 999k -ls
6029497 1000 -rw-r--r-- 1 r2d2 r2d2 1022975 Feb 17 02:55 ./large1_v1.log
6029498 1000 -rw-r--r-- 1 r2d2 r2d2 1022976 Feb 17 02:55 ./large1_v2.log
$
##################
More tests follow:
$
$ # size 1k = sizes in the range (0k, 1k] or (0, 1024]
$ find . -type f -size 1k -ls
6029492 4 -rw-r--r-- 1 r2d2 r2d2 183 Feb 17 02:29 ./graphical.txt
$
$ # size 2k = sizes in the range (1k, 2k] or (1024, 2048]
$ find . -type f -size 2k -ls
$
$ # size 3k = sizes in the range (2k, 3k] or (2048, 3072]
$ find . -type f -size 3k -ls
6029493 4 -rw-r--r-- 1 r2d2 r2d2 2112 Feb 17 02:29 ./strace.out
$
$ # size 4k = sizes in the range (3k, 4k] or (3072, 4096]
$ find . -type f -size 4k -ls
$
$ # size 5k = sizes in the range (4k, 5k] or (4096, 5120]
$ find . -type f -size 5k -ls
6029494 8 -rw-r--r-- 1 r2d2 r2d2 4659 Feb 17 02:29 ./vmstat.out
6029495 8 -rw-r--r-- 1 r2d2 r2d2 4660 Feb 17 02:30 ./vmstat1.out
$
$
So essentially, if a file is using up:
(a) 10.3 blocks i.e. 10 blocks + a fraction of the next block, then its size is considered to be 11 blocks
(b) 4k blocks + a fraction of the next 1k block, then its size is considered to be 5k blocks
(c) 2M blocks + a fraction of the next 1M block, then its size is considered to be 3M blocks