I ran and returned as below:
echo $'\0' | cat -vet
$^@$
echo -e '\0' | cat -vet
-e ^@$
/usr/bin/printf '\0\n' | cat -vet
^@$
What does it mean?
I ran and returned as below:
echo $'\0' | cat -vet
$^@$
echo -e '\0' | cat -vet
-e ^@$
/usr/bin/printf '\0\n' | cat -vet
^@$
What does it mean?
do yo mean the result of this echo $0 | cat -vet?
echo $0 | cat -vet
-ksh$
'awk -v nul="$(printf '\000')" ' is replace with awk -v nul="$'\000'" '$' and no warning message is returned.
cat -vet out-data-file-zero.del
"$'^A^B^C^D^E^F^G^H^I","^P 0@P`p",,,$
"M-^@M-^AM-^BM-^CM-^DM-^EM-^FM-^GM-^HM-^I","M-^PM-^QM-^RM-^SM-^TM-^UM-^VM-^WM-^XM-^Y",,,$
#!/bin/bash is replaced with #!/usr/bin/ksh93,nul: that means using /bash or /ksh93, the result is same.awk -v nul="$(printf '\0')" ' is used.
cat -vet out-data-file-zero.del
"^A^B^C^D^E^F^G^H^I","^P 0@P`p",,,$
"M-^@M-^AM-^BM-^CM-^DM-^EM-^FM-^GM-^HM-^I","M-^PM-^QM-^RM-^SM-^TM-^UM-^VM-^WM-^XM-^Y",,,$
That's good enough, thanks.
Could we try one more thing. Change the she-bang line (in the latest script) to #!/usr/bin/ksh93 and run the script again.
And drop nohup from the execution line.
#!/usr/bin/ksh93, see the result in 2. of my previous postthe original data: this is just a sample there are 74 fields in a record.
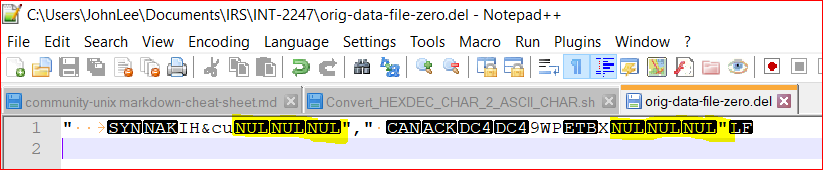
![alt text]
these ascii characters converted to hex decimal format as below to resolve issues caused by special characters in it:
"20200916154948266375000000","20180614143957501758000000"
after that, process these records and change some field's value and / or delete some records if matching condition is met and write it back to original record format as seen above image posted.
I've managed with help from vgersh99, MadeInGermany and jgt, to this far and my final challenge is to replace hex 00 to ASCII character NUL as seen from the image of original data.
well... I guess my bright idea wasn't as bright as I'd hoped - happens to me quite a bit lately (yes, it's a lame attempt at being funny - thought I'd mention it).
Seems like we cannot trick AiX awk - let's try to post process awk's output and trick it that way.
Change:
awk -v nul="$(printf '\000')" '
to
awk -v nul="$(printf '%b' '\350')" '
execute the script as:
./myScriptName.sh myFile2process | tr '\350' '\0'|cat -vet
Let's see what comes out
Wow! this time is something different..
./Convert_HEXDEC_CHAR_2_ASCII_CHAR.sh in-data-file-zero.del | tr '\350' '\0'|cat -vet after I replace with this awk -v nul="$(printf '%b' '\350')" ' and the result is:"^@^A^B^C^D^E^F^G^H^I","^P 0@P`p",,,$
"M-^@M-^AM-^BM-^CM-^DM-^EM-^FM-^GM-^HM-^I","M-^PM-^QM-^RM-^SM-^TM-^UM-^VM-^WM-^XM-^Y",,,$
awk -v nul="$(printf '%b' '\350')" ', what %b and \350 is for?%b but my understanding is replace whatever %b is to \350, correct?| tr '\350' '\0'|cat -vet is for? is it to replace \350 to \0?^@ is :.
.
if (i%2==0) {
x=px*16+x
if (x==0 && px==0) { v=v "^@" }
else { v=(v sprintf("%c",x?x:nul)) }
}
else { px=x }
.
.
NUL for hex00.Thanks in advance!
do man printf to find out the meaning of the %b formatting option:
%b ARGUMENT as a string with '\' escapes interpreted, except that
octal escapes are of the form \0 or \0NNN
tr '\350' '\0' - replace octal 350 with octal 0. For the rest, refer to man tr
cat -vet should be self-explanatory by now...
I think/hope (a joke) there's no "next" as the initial Q has been covered in more details than initially expected. The "take away" I think is for you to understand the pieces to the final solution and what issue we (ALL of us) had to overcome.
I think this thread came be closed with the proper post marked as a solution. I'll leave it up to the OP/@sandjlee to work out the closing logistics.
You're welcome.
In the nut shell. The last hurdle we had to overcome was the AiX awk inability to deal with the "null byte" as indicated by:
./Convert_HEXDEC_CHAR_2_ASCII_CHAR.sh: line 2: warning: command substitution: ignored null byte in input$
As we determined that AiX awk couldn't deal with ASCII NUL, we (ALL of us) decide to encode the ASCII NUL as ASCII octal 350 (probably could be any octal over 255 ASCII range) coming out of the script and convert it back to ASCII NUL (octal 0) by something other than awk that we hoped no such limitation. Seemed like AiX tr had no issue dealing with the conversion.
Bottom line, mnemonic approach dealing with ASCII NUL:
encode ASCII NUL as something else by awk -> decode the encoded char(s) back to ASCII NUL
NOTE: was thinking we could eclipse the number of posts for a single thread record set by Share a Classic Rock Music Video from the 1960s and 70s, but we've come very close. I don't think we need a recount ![]()
Dear vgersh99,
Thanks for your help with your expert knowledge in awk and shell script on this thread.
I am waiting two more answer from you:
./myscript.sh .... was used. what is ./ and when does it need?Thanks in advance!
the ./ means find myscript.sh in the current working directory. If you run the script withOUT leading ./, shell will try to locate myscript.sh using the env var $PATH - which might NOT include the current working directory (./). I'll let you Google for a more detailed explanation.
ASCII NUL is 0 (or 00 or 00000) in any representation: decimal, octal, hex or any other N-based representation. Do ascii from the shell to see the ASCII table. Google for the relative terms for the more detailed explanation.
I owe you my soul for your help!
Thanks and stay safe wherever you are.
John
Update.
When I performed regression test with a big file, noticed that quotation in a middle of field causing an issue. it is hex decimal value 22 (x=34) and it need to be converted as ascii character "" (double quotations) because when it is imported back, "" is loaded as a single quotation (").
therefore, I changed the function hex2str as below if (x==34):
# return the unhexed h string
function hex2str(h, i,x,px,v) {
h=tolower(h); sub(/^0x/,"",h)
for(i=1;i<=length(h);i++) {
x=index("0123456789abcdef",substr(h,i,1))-1
if (i%2==0) {
x=px*16+x
if (x==0 && px==0) { v=v nul }
else
if (x==34) { v=(v sprintf("%c",x?x:nul));
v=(v sprintf("%c",x?x:nul))
}
else { v=(v sprintf("%c",x?x:nul)) }
}
else { px=x }
}
return v
}
To be honest, I don't understand:
22" means. It's either decimal OR hex, it cannot be "hex decimal""" is loaded as a single quotation (")." Is it single quote or one double quote? I don't follow your explanation.But either way... If you have double quotes in the cab file, it usually means that you can potentially have an embedded comma in the field that needs to be distiguishéd from the cab field separator (CSV).
By simply removing double quotes could potentially break whatever data you're importing.
I'd be carefully by not simply "making it work" by tweaking the code, but rather considering the end result and the integrity of the imported data.
The integrity of the massaged data has already been discussed in this 72-posts thread in the number of posts already. No need to go over it again.
I'll let you reread the above and think about it and make whatever call you feel comfortable with.
Good luck with that.
I may need to clarify about below:
it is hex decimal value
22(x=34) and it need to be converted as ascii character""(double quotations) because when it is imported back,""is loaded as a single quotation (")
you are correct. It should be read as hex value 22 not as hex decimal 22.
My issue was, after converted to a single quotation (") , I tried to import / load using db2 utility using a field contains a single quotation into one of the column in db2 table, and is caused a problem to resolve this issue, hex 22 need to converted to double quotation.
It may be depends on the need but for my case, double quotation is the solution. -eom-
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.